
工作经常碰到负载过高,cpu占有太高,系统变慢,运维通常做的第一件事就是通过top或者uptime命令来了解系统负载的情况
通常uptime后会出现三个小数,就是平均负载值,那真正的了解这个平均负载值吗?
![]()
大多数运维小哥会说:平局负载不就是cpu使用率吗?上面三个数字分别代表不同时间段的cpu使用率吗?
其实并不是这样的.......
平均负载的详细解释:平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数!和cpu使用率并没有直接关系
如果是工作中所期盼的,我们都希望平局负载最理想的状态的是等于cpu个数,所以,在通过命令来了解平均负载之前,我们应该先知道cpu的个数,才能更好的知道负载状态
#grep 'model name' /proc/cpuinfo | wc -l
![]()
当知道cpu个数后,如果平局负载值超过个数,就说明系统负载过高!!!
可是这样看来,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗?
这里还得从理论来分析:平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
由此可见!CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。
比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的。
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一 定很高。
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
这里做一个小实验
模拟负载过高,来做分析
这里我用到的系统是 :
| 系统: | RedFlag-Asianux-7.6 |
| 内核版本 | 3.10.0-957 |
注:其他的linux系统也可以做
要下一个压力测试包:stress-1.0.4-6.7.rpm
这个包各大镜像站网源有,可以查到并下载
这里分析两个立志;一个是模拟cpu使用率过高 | 一个模拟I/O压力过大
案例一:
下载安装后,开启三个终端,并在一个终端进行施压模拟,同时在另外两个终端进行排查分析
第一个终端: 模拟施压
#stress --cpu 1 --timeout 500

第二个终端: 查看平局负载
#uptime
#watch -d uptime

第三个终端; 找出引起负载过高的进程
#pidstat -u 5 1

案例二:
模拟i/o压力,首先还是使用stress命令来测试
第一个终端:
#stress -i 1 --timeout 600

第二个终端:
#uptime
#mpstat -P ALL 5 1

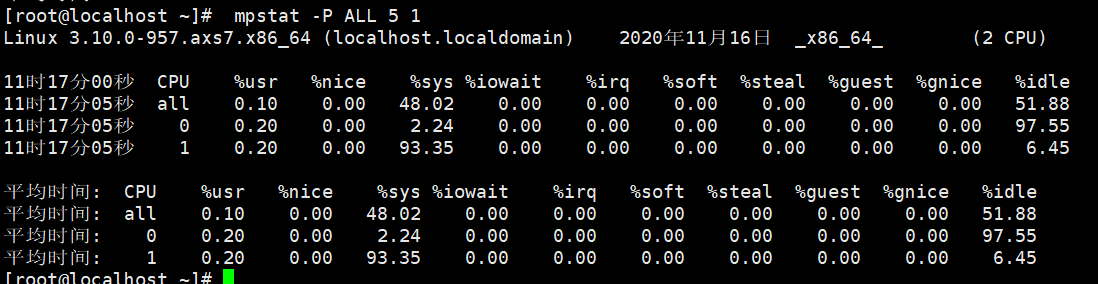
通过mpstat可以看出,平局负载过高是iowait引起的,那么到底是哪个进程,导致 iowait 这么高呢?我们还是用 pidstat 来查询(如:案例一)
综上所例:
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
(1)平均负载高有可能是 CPU 密集型进程导致的;
(2)平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
(3)当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源